J’entends de grandes inquiétudes sur le fonctionnement du suivi contacts qui sera instauré en France pour prévenir la propagation du COVID-19. J’entends en particulier des craintes concernant la sécurité des informations et la capacité de l’État à utiliser ces informations pour traquer les citoyens.
Je ne suis pas un spécialiste en sécurité ou en RGPD mais je vais montrer ici ce qu’est le “privacy by design” dont on entend parler et pourquoi il existe un compromis en sécurité et fonctionnalités.
Attention: Ce post est destiné au grand public, si vous êtes du métier, vous saurez déjà tout ce qui est écrit ici ! Je vais également simplifier des concepts pour faciliter la compréhension.
Dans les exemples suivants, nous suivrons Alice et Bob, deux amis qui n’habitent pas ensemble mais qui se sont rencontrés au supermarché. 2 jours après, Alice commence à présenter les symptômes du COVID-19, il faut donc prévenir toutes les personnes qu’elle a croisé dans les jours précédents.
Solution 1 : 1984
Pour ce premier scénario extrême, nous prenons le pire scénario : celui où le système mis en place stocke toutes les informations sur tous les déplacements de tout le monde. Il s’agit du scénario idéal car il permet un contrôle total mais il ne protège pas les données d’Alice et Bob qui sont obligés de faire confiance au système.
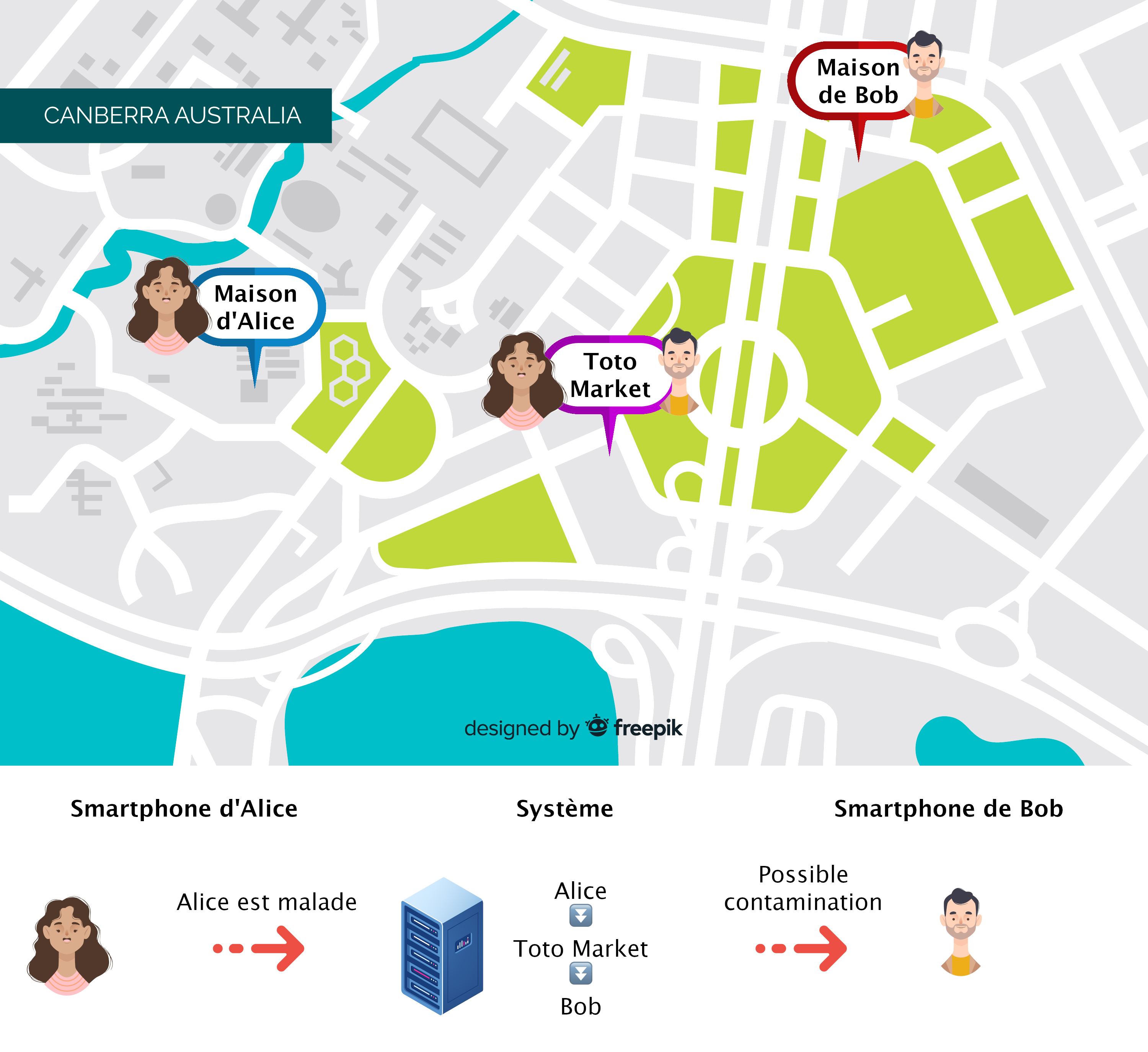
Avantages : Système robuste et sûr : toutes les personnes contaminées peuvent être identifiées
Inconvénients : Un système mal intentionné peut tirer partie des informations utilisateurs
Solution 2 : Anarchy in the UK
La deuxième solution est une décentralisation totale. Le téléphone va se connecter aux autres smartphones proches par Bluetooth et garder une trace de ce contact. Il paraît évident qu’il n’est pas désirable que chaque personne possède le nom de toutes les personnes qu’elle a croisé car nous n’avons pas de preuve qu’elles se connaissent. Nous gardons donc un système centralisé
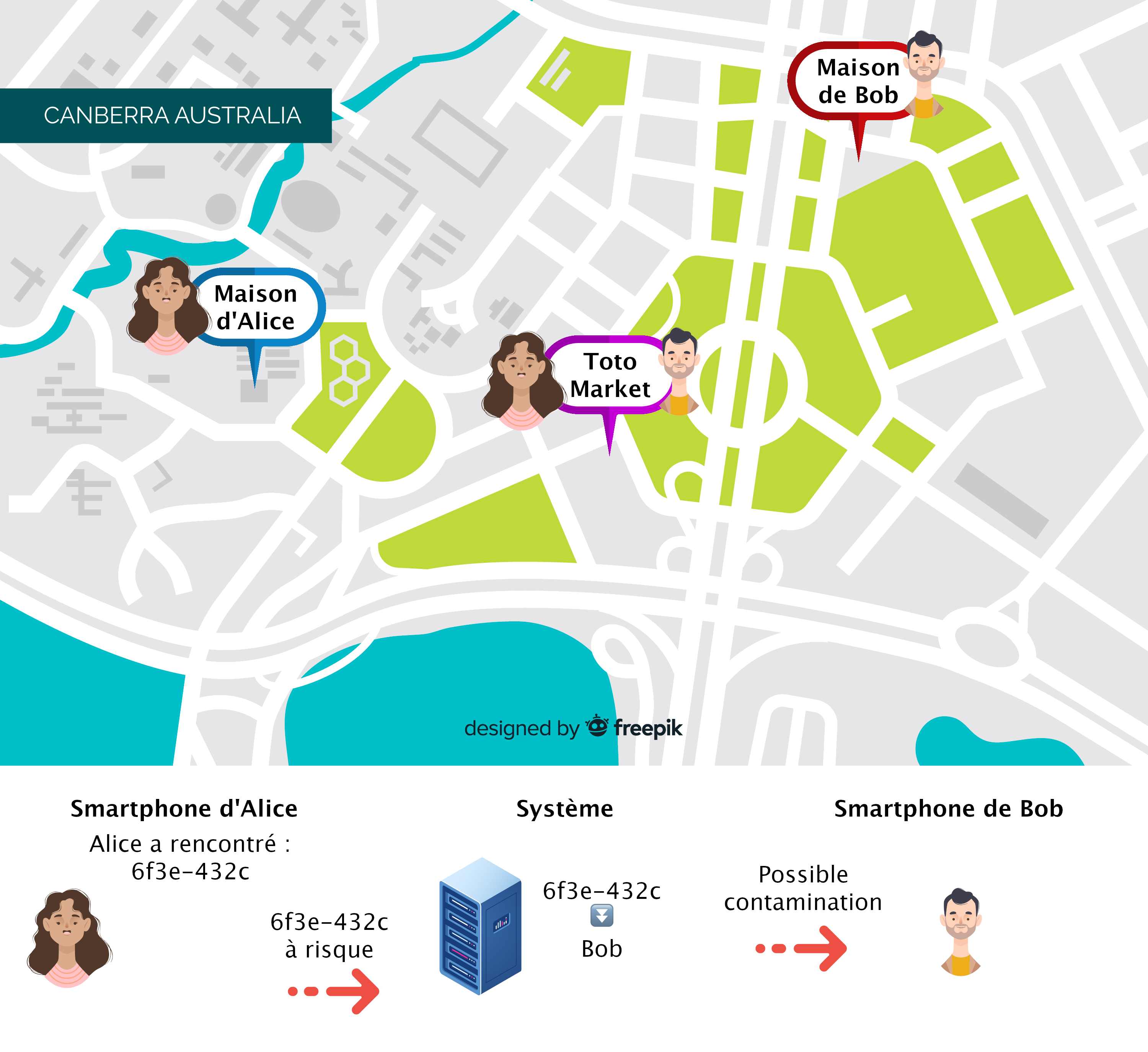
Le problème ici est que la confiance réside entièrement dans les utilisateurs. Ainsi, si un personne ne veut pas être mise en quarantaine, elle peut décider de ne pas donner de signal. De même, si un téléphone tombe en panne, c’est tout l’historique de cette personne qui est perdu.
Avantages : Anonymisation totale
Inconvénients : Peu résilient aux pannes
Solution 3 : FBI, Fausse Bonne Idée
On pourrait maintenant penser qu’associer les deux solutions précédentes serait une bonne idée. Essayons donc d’anonymiser les parcours mais de les stocker sur un serveur.
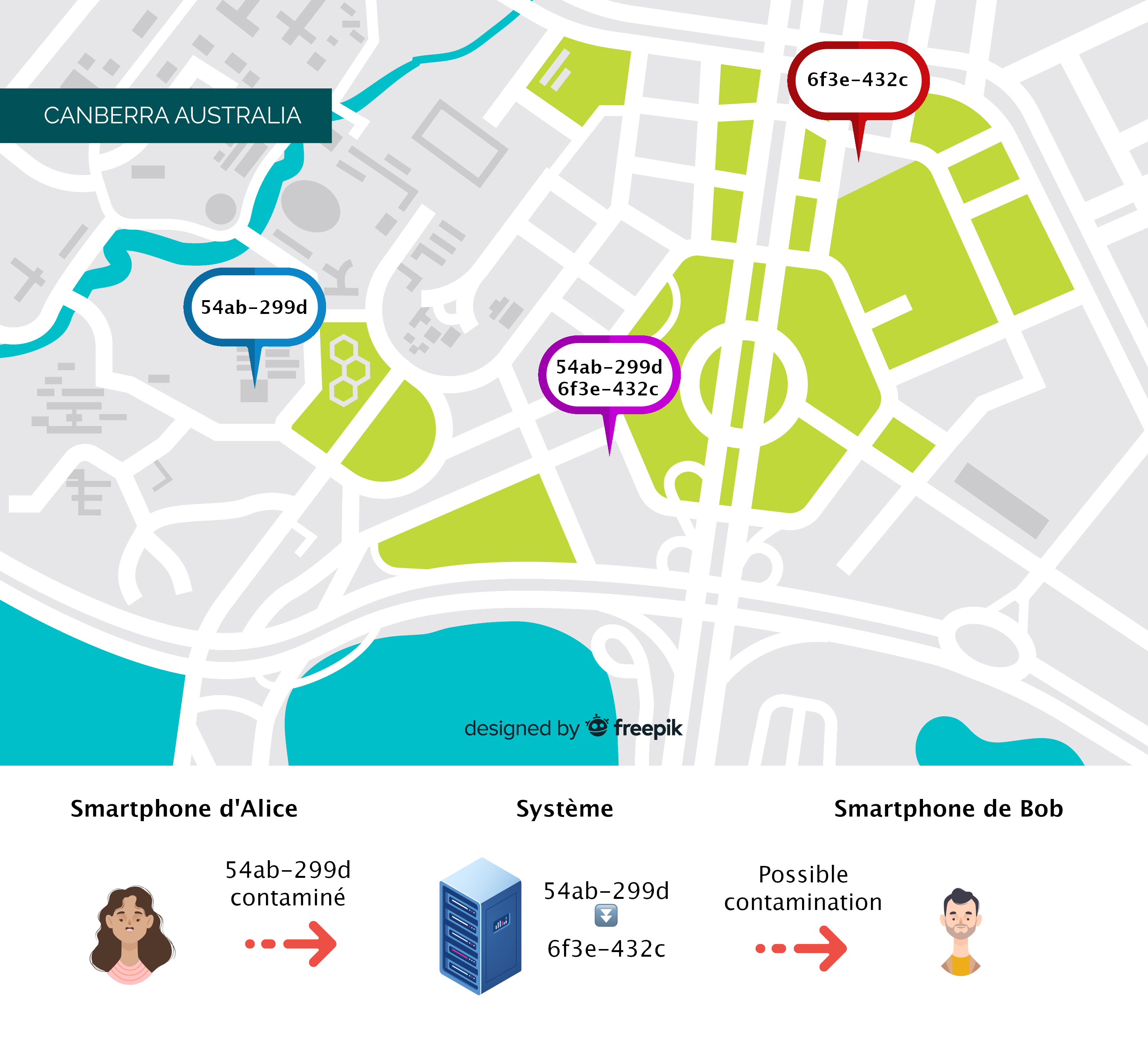
Ce procédé qui consiste à remplacer le nom d’une personne par un identifiant unique est appelé “pseudonymisation”. Pour que celui-ci soit efficace, il faut non seulement remplacer le nom par un pseudonyme mais il faut également s’assurer que les autres informations présentes dans les données ne permettent pas d’identification. Or, si l’on possède l’historique de localisation d’une personne, il est relativement aisé de l’identifier à condition d’avoir accès à quelques informations supplémentaires. Si l’on possède l’adresse d’une personne et son lieu de travail, il doit être relativement simple de retrouver son identifiant unique par exemple.
- Robuste aux pannes
- Sans information complémentaire, identifier une personne est difficile
Inconvénients : Trouver les informations nécessaires pour identifier une personne en particulier n’est pas très difficile.
Solution 4 : Un bon compromis
Maintenant que nous avons vu les forces et les faiblesses de plusieurs systèmes, résumons ce que nous voudrions idéalement:
- Personne ne doit pouvoir lier les utilisateurs à leur localisation
- Il ne doit pas être possible de consulter l’historique de localisation complet d’un utilisateur
- Le système doit être résilient aux pannes et bien notifier toutes les personnes qui ont été en contact avec une personne infectée
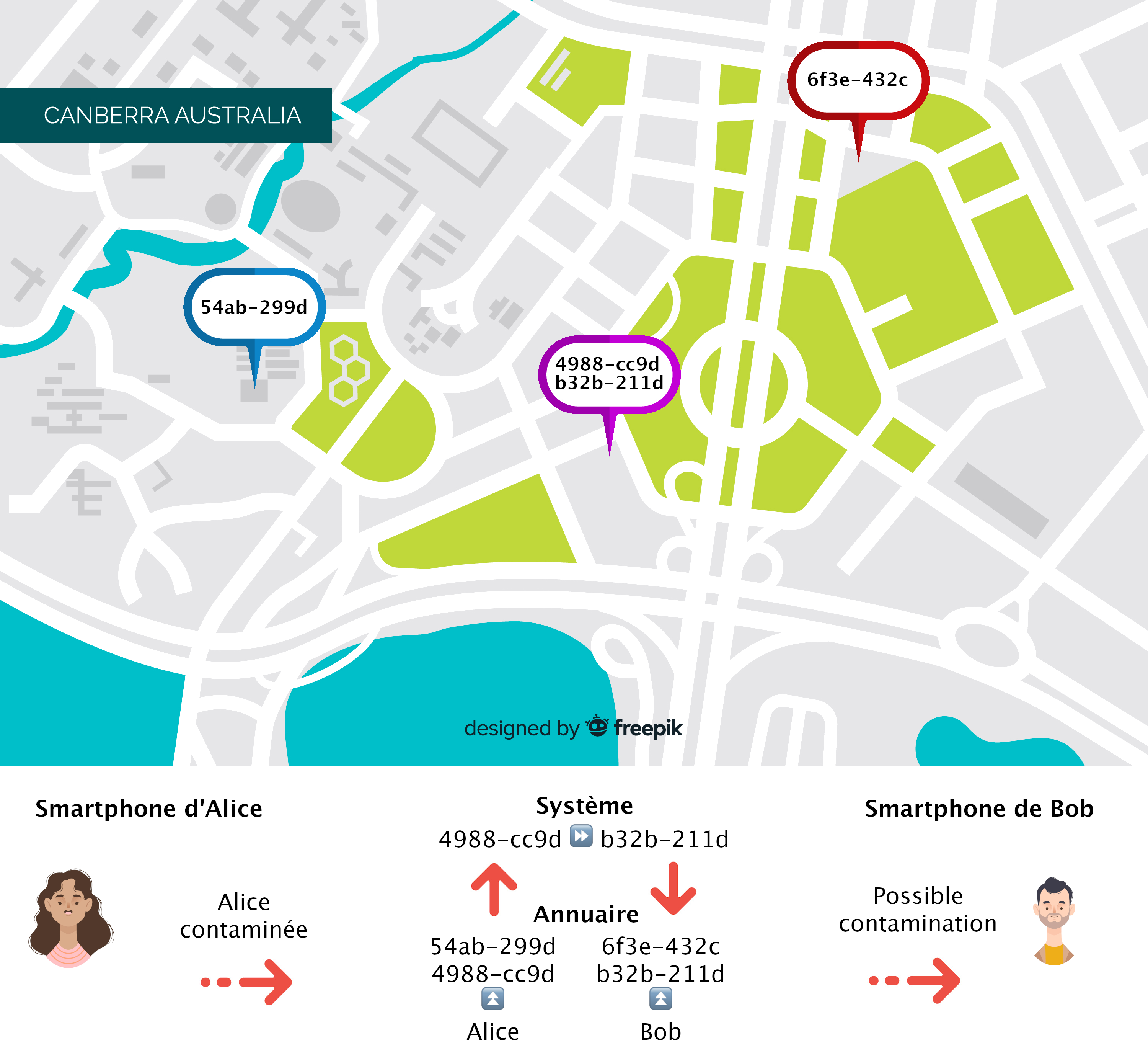
Pour pouvoir respecter toutes ces contraintes, une solution est d’introduire un nouvel acteur dans notre système qui sera en charge de réaliser l’identification et de conserver notre système en charge de trouver les personnes mises en contact. En faisant cela, nous voyons qu’à aucun moment il n’est par exemple possible de savoir qu’un potentiel infecté est présent dans la maison de Bob car il n’est jamais fait de lien entre l’identité de Bob et ses différentes localisations.
- Robuste aux pannes
- Croiser les informations pour obtenir les déplacements d'une personne est très complexe
- En introduisant un nouvel acteur, le coût de la solution est bien plus élevé
Conclusion
Comme vous le voyez, stocker des informations est nécessaire pour être robuste aux pannes et aux attaques externes malveillantes. On peut toutefois concevoir un système qui rend l’extraction d’information plus coûteuse que ce qu’elle pourrait rapporter. Il existe de nombreux autres designs qui permettraient d’avoir les mêmes fonctionnalités avec de meilleures garanties mais j’ai souhaité m’en tenir aux plus simples. Il est probable que cette solution ne soit pas celle qui soit mise en place car je suppose qu’il serait intéressant de prévenir les membres du foyer de Bob, probablement en leur signifiant un risque d’infection plus faible.
Crédits
Tous les graphiques utilisés dans les diagrammes proviennent de Freepik.