Data labeling is a tedious yet necessary task to train Machine Learning models. This iterative process alternates data labeling and model training. Active Learning proposes to lower the cost of this process by using the already labeled data to select the new samples to send to the annotator.
However, Active Learning is used most of the time for one-shot experiments. How to choose the best query sampling method, then? Should one pick the best performer on a similar task even though it fails in other ones? Or the one that always performs slightly better than random?

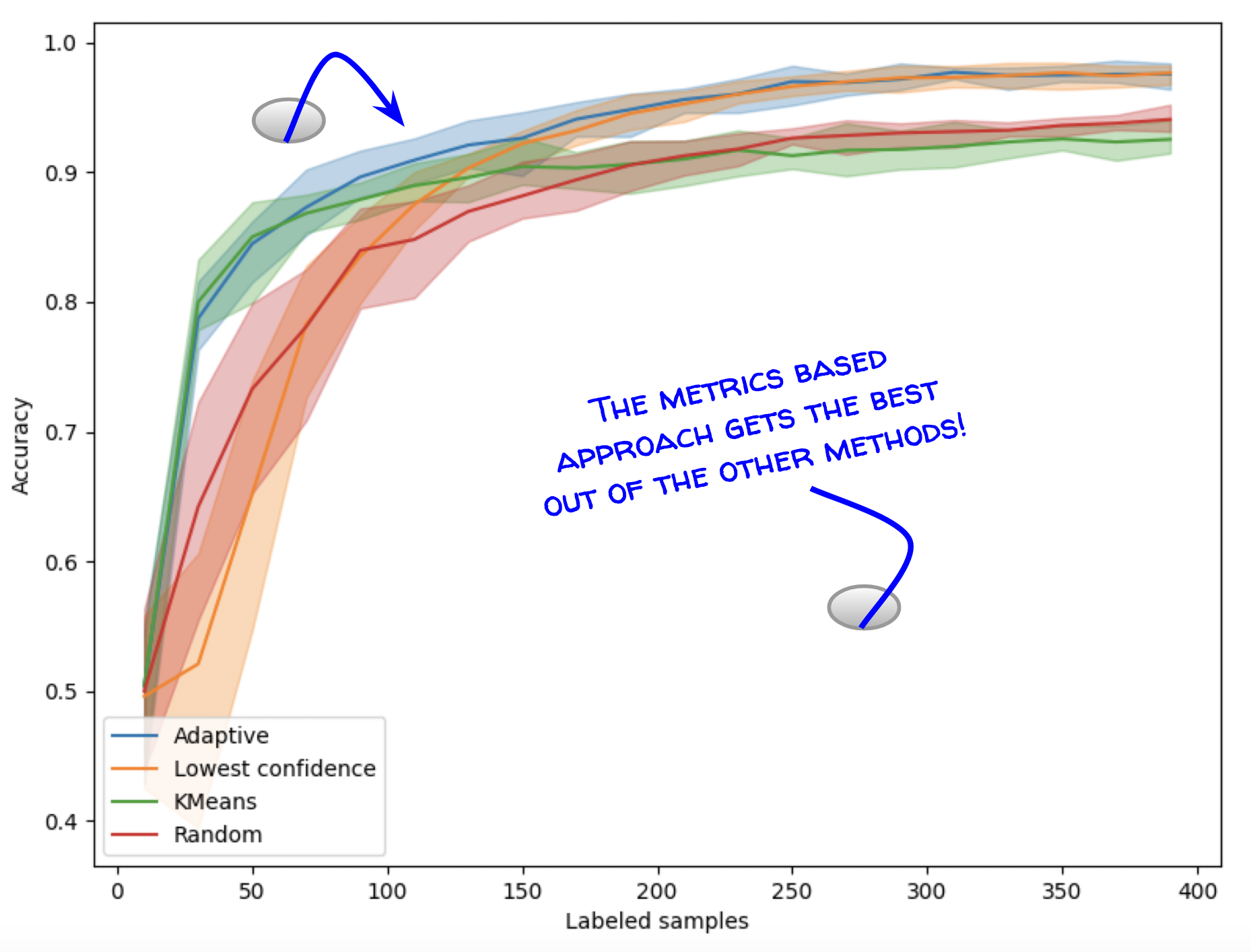
Cardinal answers this question by providing metrics guiding the practitioner in its decision. Contrary to common metrics that are based on a left-out labeled set, our metrics are completely unsupervised and can be computed without any additional cost. In our experiments, cardinal not only helped select the best strategy but even outperformed it in some cases! See this example for more information.
Want to know more? Attend my PyData talk on Friday at 9:30am and 1:15pm UTC!